
Nicht erst seit dem Hackerangriff auf das Netz des Bundestages oder den Vorfällen rund um die US-Wahl ist Cyber Security in aller Munde. Fast täglich hört man von der unautorisierten Nutzung von Daten wie zuletzt durch Cambridge Analytica. Doch während viel über die potenziellen Gefahren geschrieben wird, liest man nur wenig darüber, wie man sich schützen kann.
Für Privatleute ist eine Änderung ihrer privacy policies bei Facebook, Twitter, Instagram oder das komplette Löschen ihrer Profile eine mögliche Handlungsoption. Eine private Firewall und einen Virenscanner auf dem eigenen PC zu betreiben ist das Mindeste, wenn man sich nicht dem Vorwurf der Fahrlässigkeit aussetzen will.
Doch was tun Unternehmen, um sich zu schützen? Wie schützt man ein Firmennetzwerk erfolgreich vor Angriffen von außen und noch viel wichtiger, wie schützt sich ein Unternehmen vor dem Abfluss kritischer Daten von innen?
Für den aktiven Schutz gegen Angriffe von außen sind Firewalls, Vierenscanner, Intrusion-Detection-Systeme und Proxys für den Webzugriff längst ein etablierter Standard.
Aber ein Hauptteil der Verteidigung besteht darin, den Angriff überhaupt erstmal zu erkennen. Und diese Arbeit ist in einem heterogenen IT-Umfeld, wie es in den meisten Unternehmen vorherrscht, eine nicht zu unterschätzende Herausforderung.
Das sogenannte Security Information and Event Managment (SIEM) ist eine Grundlage, um Angriffe zu detektieren und forensische Untersuchungen früherer Vorfälle vorzunehmen. Aber was verbirgt sich hinter diesem etwas sperrigen Begriff?
SIEM ist die Kombination aus mehreren Bauteilen
Das Logdaten Management (LM) ist für eine zentrale Sammlung der Logdaten und deren revisionssicheren Speicherung verantwortlich.
Das Security Information Management (SIM) definiert basierend auf den zentral gesammelten Logdaten Maßnahmen zur Gewährleistung der Datenintegrität und Vollständigkeit. Integrität und Vollständigkeit der Logdaten wiederum bilden die Grundlage für IT-Forensik aber auch für Untersuchungen zur Einhaltung der Service Level Agreements. Schon allein anhand der Zentralisierung der Logs ist es möglich, Alarmierungen für „auffällige“ Angriffe wie DDoS oder Brutforce-Attacken zu treffen.
Das Security Event Management (SEM) unterstützt dabei auch ausgeklügeltere Einbruchsversuche oder unberechtigte Zugriffe von innen aufzudecken, indem verschiedene Log-Events korreliert werden. Es bedarf zusätzlich einer Schwachstellenanalyse der eingesetzten Software sowie eines Berechtigungsmonitorings für die eigenen Mitarbeiter, um das SEM zu komplettieren.
Ein SIEM benötigt „aussagekräftige“ Logdaten, um seine Aufgabe erfüllen zu können. Die Aussagekraft von Logdaten orientiert sich zum einen am Schutzbedarf der verschiedenen Anwendungen und zum anderen an den zu detektierenden Vorfällen. An dem folgenden Beispiel kann man sehen, was damit gemeint ist:
Auf einem Serversystem ist eine Datenbank installiert, welche personenbezogene Daten enthält. Der Zugriff auf die Daten erfolgt ausschließlich über eine Applikation und den technischen User, der in der Applikation verwendet wird. Eine missbräuchliche Nutzung könnte z.B. dann vorliegen, wenn:
- versucht wird, die Konfiguration der Datenbank zu verändern,
- Abfragen mit einem SQL- Kommandozeilenwerkzeug gegen die Datenbank gemacht werden,
- versucht wird, auf der Systemebene die Datenbankdateien zu lesen
- versucht wird, das Passwort des Datenbank-Admins zu verändern
- etc.
All diese Vorgänge müssen also Log-Events erzeugen, damit eine missbräuchliche Nutzung erkannt und von einer legitimen Nutzung (z.B. das Backup liest die Datenbankdateien) unterschieden werden kann.
Dabei gilt es, die potenziell gefährlichen Vorgänge zu identifizieren und das Logging so zu konfigurieren, dass aus dem Log ersichtlich wird, wer den Vorgang vornimmt und wie dieser Benutzer zu den entsprechenden Rechten gekommen ist.
Dazu muss in der Regel eine Korrelation zu den Events aus dem Berechtigungsmanagement und gegebenenfalls zu Change und Incident Management erfolgen. Bei all diesen Fragen spielt oft die zeitliche Abfolge oder die Zeitspanne eine entscheidende Rolle.
Big-Data-Logdaten-Suchmaschine "Splunk"
Je nach Anwendungslandschaft und deren Bedarf an Vertraulichkeit, Integrität, Verfügbarkeit und Authentizität kann also, um aussagekräftige Logdaten zu erhalten, ein erhebliches Log-Volumen bis hinzu mehreren Terabyte pro Tag entstehen.
An dieser Stelle wird klar, dass ein leistungsstarkes SIEM-Tool eine Notwendigkeit ist, um diese Aufgabe bewältigen zu können. Einer der prominentesten Vertreter dieser Tools ist Splunk, über dessen Funktionen im Folgenden ein Überblick gegeben wird.
Splunk ist eine Big-Data-Logdaten-Suchmaschine, das heißt, es sammelt die Logdaten aus den verschiedensten Logquellen und indexiert sie. Dabei bestimmt der Splunk-Architekt beim Aufsetzen und Erweitern des Systems, wie Logdaten klassifiziert, sprich in welchen Index die Daten kommen und welchem Sourcetyp sie zugeordnet werden sollen.
Er wird dabei von der internen Splunk-Knowledgebase unterstützt, die bereits hunderte von Eventformaten automatisch erkennt und den richtigen Sourcetypen zuordnet. Die Einordnung in Indizes ist letztlich eine Frage der Zugriffssteuerung und Zugriffsgeschwindigkeit, welche vom Architekten zu planen sind.
Splunk unterscheidet sich von seinen Mitbewerbern im Wesentlichen durch die horizontale Skalierbarkeit und die Möglichkeiten seiner Search Processing Language (SPL). Diese kann mit mehr als 140 Kommandos für statistische Suchen, die Berechnung von Metriken oder die Suche nach bestimmen Datenkonstellationen aufwarten.
Mit wenigen Kommandos lassen sich aus tausenden Events aussagekräftige Charts erstellen, die eine „abnormale Datenkonstellation“ sofort sichtbar machen.
Eine weiter Stärke von Splunk ist, dass zum Zeitpunkt der Indexierung keine Normalisierung der Logdaten erfolgt, sondern der Originalevent auch für spätere Feldanreicherungen unverändert bereit steht. Das bedeutet, dass erst zum Suchzeitpunkt festgelegt werden kann, welche Teile des Events in einem Feld abgelegt und als Auswertungskriterium herangezogen werden sollen.
Mit Hilfe von sogenannten Datenmodellen lässt sich in Splunk eine View auf die Daten erstellen, die es ermöglicht, z.B. Events der verschiedensten Berechtigungssysteme mit einer Anwendung nach den gleichen Kriterien zu bearbeiten und so plattformübergreifend Aussagen treffen zu können. Trotzdem bleibt für plattformspezifische forensische Untersuchungen das Original-Event unverändert zugreif- und auswertbar.
 Splunk-Dashboard: Aus tausenden Events werden aussagekräftige Charts
Splunk-Dashboard: Aus tausenden Events werden aussagekräftige Charts
Die Splunk-Instanzen
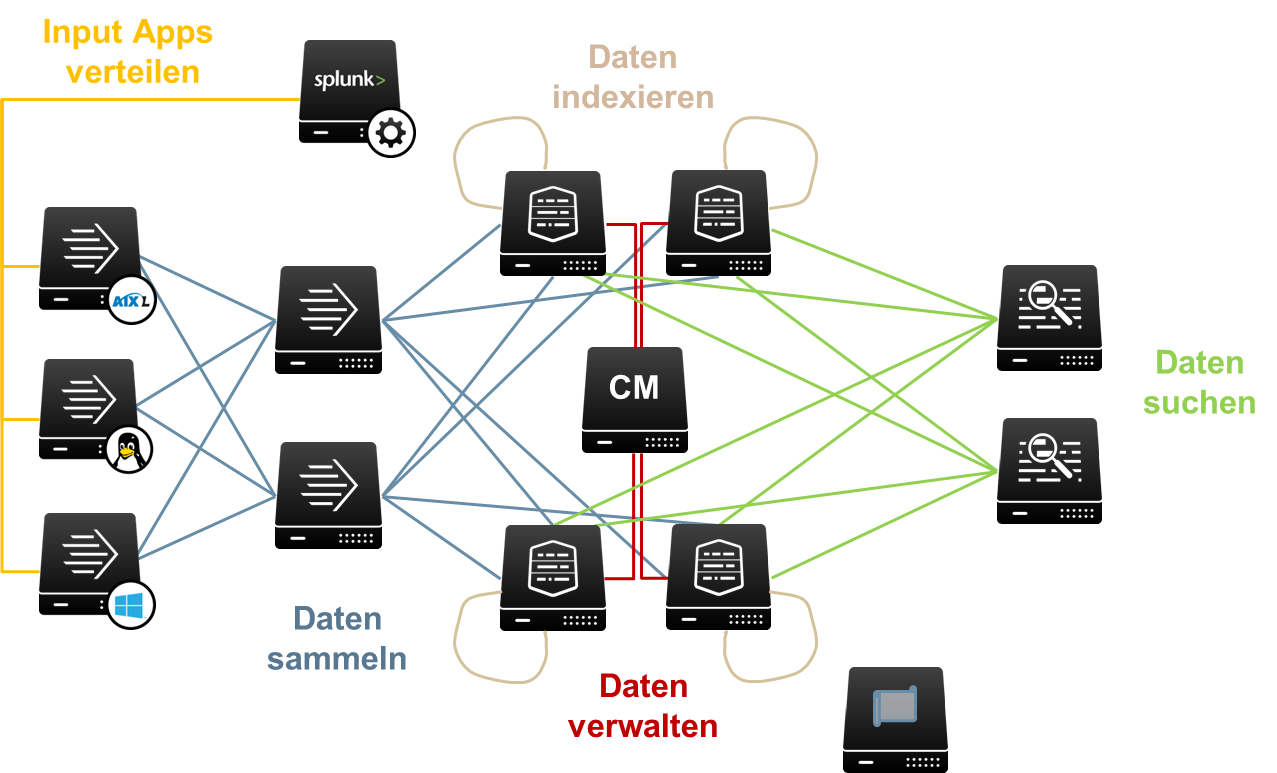
Eine Splunk-Installation besteht im einfachsten Fall aus einer einzelnen Instanz, die Daten erhebt, sie indexiert und die Suche in den Daten ermöglicht. Die volle Leistungsfähigkeit von Splunk entfaltet sich aber erst in einer „distributed environment“, in dem jede Splunk-Instanz spezialisiert auf eine Aufgabe ausgelegt ist und nur einen Teil der Verarbeitungspipeline abbildet:



Universal Forwarder: Daten sammeln und weiterleiten

Intermediate oder Heavy Forwarder: Daten parsen und Feldanreicherung

Indexer: Daten indexieren, Daten suchen, Datenalterung

Search Head: Suchanfragen parsen und an Indexer weiterleiten, Ergebnisse aufbereiten und visualisieren

Cluster Master: Verwaltung von redundant ausgelegten Indexern

License Master: Überwachung des Lizenzvolumens, Bereitstellen von Lizenzen

Deployment Server: Verteilung von Splunk-Apps auf andere Infrastrukturkomponenten Ein hoch verfügbares „distributed environment“ unter Beteiligung all dieser Komponenten könnte wie in Grafik 1 abgebildet aussehen:
Beim Indexieren werden automatisch Felder in dem Event bestimmt (weitere Felder lassen sich hinzufügen) und die Werte dieser Felder in ein Verzeichnis im Bucket eingetragen. Über die Werte der Felder kann hinterher schnell nach Events gesucht werden (Feldextraktion zum Indexing-Zeitpunkt).
Ein Feld ist stets das Raw Event, wie es der Log-Datei entnommen wurde. Es besteht auch die Möglichkeit, erst zum Zeitpunkt der Suche in dem Raw Event Felder zu bestimmen (z.B. mit regulären Ausdrücken), über deren Werte gesucht werden kann. Dabei gilt: Feldextraktion zum Indexing-Zeitpunkt bedeutet mehr Speicherbedarf und höhere Lizenzkosten, Feldextraktionen zum Suchzeitpunkt kosten Zeit.
Eine Suche bezieht sich immer auf einen Zeitbereich, der absolut (z.B. am 13.05.2016 zwischen 15:00:00 und 18:00:00 Uhr) oder relativ (z.B. in der letzten halben Stunde) definiert werden kann. Der Zeitbereich definiert also einen ersten Filter für die Events in einer Suche. Splunk-Suchen erinnern an Pipes unter Unix/Linux – durch eine initiale Suche wird eine Ausgangsmenge an Events bereitgestellt.
Diese wird dann durch das Verketten mit weiteren Kommandos über das Pipe-Symbol gefiltert oder angereichert, bis die Ergebnismenge erreicht ist.
Ergebnismengen lassen sich mit Splunk-Bordmitteln sowohl als Tabellen oder als Charts darstellen. Suchen lassen sich abspeichern (saved searches) und in sogenannten Dashboards visualisieren. Dem Betrachter wird so eine Analyse mit den aktuellen Daten in einem vorformatierten Schaubild präsentiert.
Um solche Dashboards nur definierten Benutzern zugänglich oder unabhängiger von den Gegebenheiten auf einem bestimmten Search Head zu machen, lassen sich die zugehörigen Definitionen und Konfigurationsdateien zu einer Splunk-App zusammenfassen.
Grafik 1: Beispiel für ein hoch verfügbares „distributed environment“




