
Natural Language Processing: Wie Computer verstehen lernen
Das Natural Language Processing (NLP) umfasst die maschinelle Verarbeitung der natürlichen Sprache, welche mit Hilfe von automatisierten Techniken und Methoden realisiert wird. Ultimatives Ziel ist die Kommunikation zwischen Mensch und Computer auf Basis der natürlichen Sprache.
Als essentielle Datenquellen dienen sogenannte qualitative Informationen, wie Zeitungsartikel, Audioaufnahmen, Blog-Beiträge etc.. Diese müssen im Gegensatz zu quantitativen Informationen zunächst verarbeitet werden, sodass hieraus spezifische Textstrukturen maschinell erkannt sowie verstanden werden. Für die effiziente Verarbeitung von qualitativen Datenquellen werden unterschiedliche Disziplinen aus dem Big-Data Umfeld hinzugezogen – allgemein bekannt als Text Mining.
Im Kontext meiner Master-Thesis mit dem Titel „Sharing Geschäftsmodelle – Textanalytische Entwicklung eines Modellierungsansatzes“ habe ich essentielle Methoden des NLP sowie des Text Minings genutzt. Als NLP-Tool habe ich dabei das Natural Language Toolkit (NLTK) verwendet – ein auf der Programmiersprache Python basierendes Toolkit.
Ziel war die Konzeption einer Modellierungstechnik und -sprache zur Darstellung von Geschäftsmodellen für sämtliche Sharing-Anbieter (wie bspw. Uber und Airbnb). In diesem Beitrag liegt der Fokus auf den einzelnen Steps, die ich für meine maschinelle Textverarbeitung genutzt habe.
Die maschinelle Textverarbeitung kann grundsätzlich in folgende Steps unterteilt werden:
1. Textextraktion und -aufbereitung
Durch Crawling können unterschiedliche Textinformationen automatisiert extrahiert werden. Bei einem Crawler handelt es sich um Software-Lösungen, die iterativ (textuelle) Informationen sammeln und diese nach ausgewählten Mustern bündeln.
2. Korpusaufbereitung und -erstellung
Nachdem die Textinformationen gesammelt wurden, müssen diese entsprechend verarbeitet werden. Die verarbeiteten Textinformationen bilden im Anschluss das sogenannte Textkorpus. Das Textkorpus stellt die primäre Datenbasis dar. Wesentliche Schritte bei der Korpusaufbereitung sind u.a.:
- Textsegmentierung (Sentence Segmentation): Automatisierte Segmentierung von Sätzen, indem Satzanfänge und -enden erkannt, markiert und segmentiert werden
- Tokenisierung: Erstellung von Wortlisten, indem die einzelnen Worte automatisiert erkannt und voneinander segmentiert werden
- Korpusbereinigung: Bereinigung des Textkorpus durch das Entfernen von sogenannten Stopwords (Wörter mit syntaktischen Funktionen, wie bspw. Artikel, Satzeinleitungen und Präpositionen)
- Linguistische Annotation und Normalisierung: Mit Hilfe sogenannter Tagger werden die einzelnen Tokens (Wörter im Textkorpus) mit den zugehörigen Wortarten annotiert.
Im Kontext meiner Master-Thesis entstand hieraus ein Textkorpus bestehend aus insgesamt 559.360 Wörtern.
3. Relationsextraktion
Der dritte Step der „Relationsextraktion“ beschreibt einen analytisch, statistischen Prozess zur Identifizierung geeigneter Relationen zwischen Konzepten. Hierfür werden wesentliche Konstrukte innerhalb des Textkorpus unterschiedlich in Beziehung gesetzt, sodass wesentliche Relationen erkennbar sowie darstellbar werden.
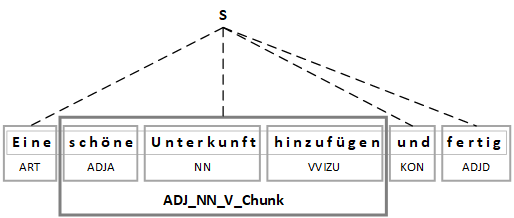
Ein Anwendungsbeispiel ist dabei die Technik des Chunking. Hierfür werden einzelne Sätze mit Hilfe von sogenannten Chunks segmentiert, welche zuvor auf Basis der annotierten Wortarten konzipiert werden können. Die folgende Abbildung illustriert beispielhaft die Anwendung eines Adjektiv-Nomen-Verb Chunks, der auf meinem aufbereiteten Textkorpus angewendet wurde.
Grafische Darstellung des Adjektiv-Nomen-Verb Chunks
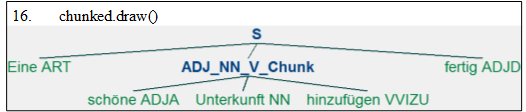
Implementierung des Adjektiv-Nomen-Verb Chunks in NLTK
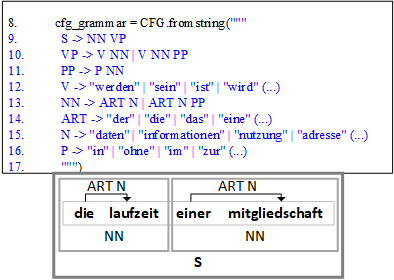
Durch das sogenannte termspezifische Parsing können u.a. explizite Relationen zwischen relevanten Wörtern identifiziert werden. So können bspw. Oberbegriffe (Hyperonym) und dazugehörige Unterbegriffe (Hyponym) ermittelt werden:
Fazit
Die skizzierten Methoden und Techniken zur maschinellen Sprachverarbeitung helfen bei der Konsolidierung, Verarbeitung und Analyse großer Textmengen. Sie umfassen jedoch nur einen Bruchteil der Potentiale und Möglichkeiten, die durch das Text Mining ermöglicht werden.
Auch in der Praxis finden diese Methoden immer häufiger an Bedeutung, wie z.B. im Assetmanagement. Die iterative Analyse der aktuellen Marktgeschehnisse spielt dabei eine wesentliche Rolle. Bereits heute kommen unterschiedliche Text Mining-Lösungen in dieser Domäne zur Anwendung.
NLP wird auch im Alltag immer wichtiger. Viele nutzen bereits die Möglichkeit, Dokumente mit dem Smartphone einzuscannen. Die enthaltenen Textinformationen werden dabei automatisiert extrahiert und entsprechend verarbeitet. Sparkassen bieten die Möglichkeit der Fotoüberweisung bereits an.
NLP und Text Mining prägen auch die Geschehnisse der anstehenden US-Wahlen am 3. November 2020. Die im journalistischen Jargon bekannte „Meinungsmache“ wird zum großen Teil durch das Auffangen der aktuellen Stimmungslage in den sozialen Medien geprägt.




